这里跟大家分享一下我是如何爬取到百度好看短视频的,分为以下的几步了,首先是打开网站http://haokan.baidu.com,建议使用chrome
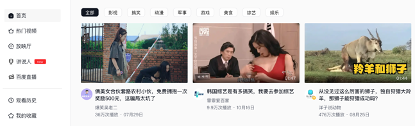
可以根据频道,然后选择其中一个用户,这里以“洋子说动物“为例,然后点击用户的头像,进入到该用户的主页。
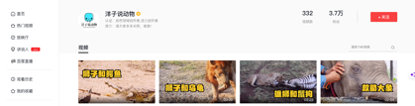
打开F12,开发者工具,然后选择“网络”-> “Fetch/XHR”,拉动鼠标向下,

在页面上会看到有视频不断的补充进来,然后网络请求栏里面,也陆续增加一些记录,这些记录是ajax的异步请求,返回的内容就是新增加进来的视频,然后我们详细查看下响应内容,
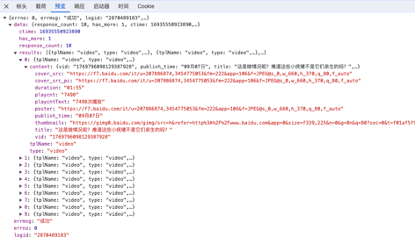
可以清楚的看到返回的格式是json,一次返回数量是10个视频,然后具体的就是每个视频的详情字段:
cover表示视频封面
duration 表示视频时长
playcnt 表示播放次数
publish_time 表示发布时间
title 表示视频的标题
vid. 表示视频的id
大家注意到这里,没有视频的播放地址,所以我们还需要打开一个视频观看,来查看视频的播放地址,
同样的打开开发者工具,然后选择“网络”-> “媒体”,可以看到视频的地址
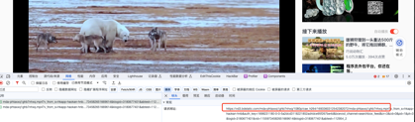
这个视频的地址有点长,然后可以通过截取的方式,提取出mp4的简洁地址。
整理下代码思路,需要2个循环,第1个 是获取这个用户的所有视频链接,提取出视频id,第2个是访问视频的播放页面,获取到视频的地址。
最后是将所有的相关视频数据存入到数据库中。
另外就是需要加一个定时任务,因为我们不知道原创作者是什么时候更新视频,所以只能通过定时来拉取,判断目前用户已发布的视频是否被我们爬取出,如果爬取过,就不爬取,如果有没爬取过的数据,就爬取一遍。就是同步原创者的更新量。
这个方案也可以通过crontab,也可以通过Python的apscheduler来实现,方法有很多,大家可以去研究一下。
Python实例代码我已经打包好了,需要的伙伴,找我私聊,发网盘链接
接下来我给大家讲解下,如何将爬取的视频全自动同步到视频号上的。